| 🎯 What’s the goal? Prevent irrelevant pages from being indexed in Search Engine Result Pages. | ⚠️ Why does it matter? To improve your Crawl Budget and give more authority to the page that matters, you might want to deindex pages with low intent such as “404” or “Thank You” pages. |
| 🏁 What’s the result? Irrelevant content is properly tagged with the “noindex” meta tag. | ⌚ When do you do this? Every time you review your sitemap, or when you create a page that shouldn’t be visible in the Search Engine Results Page. |
| ✅ Any special requirements?Administrator access to your website or WordPress. | 🙋♂️Who should do it? Pearson in charge of managing your website. |
👉 Where this is done: Yoast SEO Plugin if using WordPress Blogs or in HTML source code.
⏳ How long will this take? about 30 minutes
Let’s hide the irrelevant content from search results like a boss.

Environment setup:
- We recommend that you use Google Chrome browser to navigate the web.
- Access to your WordPress admin panel.
Why keep a post out of the search results?
“Why would you NOT want a page to show up in the search results? Well, most sites have pages that shouldn’t show up in the search results. For example, you might not want people to land on the ‘thank you’ page you redirect people to when they’ve contacted you. Or your ‘checkout success’ page. Finding those pages in Google is of no use to anyone.”
Yoast SEO blog
Another reason to exclude some of your pages from indexing is “Crawl Budget”. Crawl Budget is the number of pages Google Bot crawls and indexes on a website within a given timeframe. Google might crawl 5 pages on your site each day, it might crawl 1000 pages, it might even crawl 5000 pages every single day. Your “Crawl Budget” – the number of pages Google crawls is determined by the size of your site, the number of links to your site and by the number of errors Google encounters. Some of those factors are things you can influence.
If you want to read more about “Crawl Budget”, consult THIS article on Yoast SEO blog.
Blocking the page with “robots.txt” file will not prevent it from indexing
If your web page is blocked with a robots.txt file, it can still appear in search results, but the search result will not have a description. Image files, video files, PDFs, and other non-HTML files will be excluded.
If you want to hide the page from search results, use any method provided with this SOP.
Set page to “noindex” using WordPress plug-in Yoast SEO
Prerequisites: For this method you will need to have Yoast SEO Plugin installed on your WordPress site. Check our SOP-006 on how to do this.
- “Log in” to your WordPress Admin Panel
- Choose “Pages” from the left side menu.

- Choose the post from the list you want to exclude from Google Search Results.
For this SOP we will hide our custom “404” page.

- Mouseover the post and click on “Edit”.

- Scroll down just below the post editor and you should see Yoast SEO Plugin options. Choose the “SEO” tab.

- Reveal Advanced options by clicking “dropdown” next to it.

- Change the “Allow search […]” option to “No”.
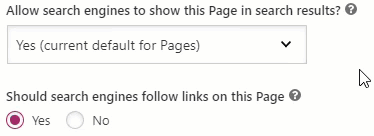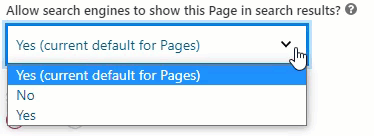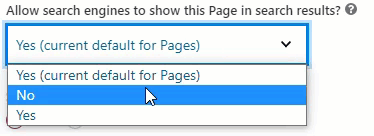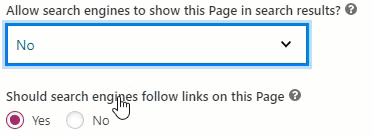
Setting this option to “No” will hide this page from Google to show it in Search Result.
You can hide for example “404” pages, any “Thank You” pages.
- If the page contains any link to another page or post that you wish to remain visible in potential Search Result leave “Should search […]” option set to “Yes”. If you want to hide it as well, set this option to “No”.

- Remember to click on “Update” to keep your settings.

Excluding page from Search Results by adding robots meta tag
You can exclude pages from Google Search Results by including a meta tag on HTML pages or in an HTTP header. This method does not apply to WordPress Blogs since they have simplified page and post editors and you can’t access the full code editor for each individual page on WordPress Blog.
If you are using a site with HTML pages or with HTTP header you can easily apply this method.
- Open the editor of your page/post and navigate to the “<head>” section.

- Now simply put the <meta name=”robots” content=”no index” /> tag inside the “<head>”.

The robots meta tag in the above example instructs search engines not to show the page in search results. Simply place it on any page that you want to hide from Google Search Results.
The value “name” defines which crawlers will not have access to your page. For example by replacing “robots” with “Googlebot” (<meta name=”Googlebot” content=”noindex” />) you prevent Google’s standard web crawler from indexing your page.
To prevent Bing’s standard crawler from indexing your page the robots meta tag should look like this: <meta name=”Bingbot” content=”noindex” />
Here you can find the top 10 web crawlers and their names.
This way you can prevent specific crawlers from indexing specific pages.
Now you can easily hide any page you want from Search Results. Analyze your content and decide which site should be excluded that way.
